

Introducing "Relative Ratings" and an all-new Matchup Preview at EvanMiya.com
A groundbreaking new team strength metric and a whole suite of new tools

Team rankings in sports are addicting. Whether it’s the AP Poll, a set of “Power Rankings”, or a preseason rankings list, debates over the exact ordering of a set of rankings can go on for ages between passionate fanbases. There are different philosophies for deciding how to order teams, but arguably the most interesting one is a theoretical head-to-head battle on the hardwood. Would my team beat your team at a neutral site tomorrow? If Duke is ranked one spot ahead of Kansas, the most common argument I hear from a Kansas fan goes something along the lines of “there’s no way Duke is better than Kansas. Duke would wipe the floor with Kansas.” This take is easy to fire off because there’s usually not a way to disprove this argument unless the two teams in question are scheduled to play each other in the next several days.
Modern-day basketball computer ratings can help answer some of these ranking debates, but they are somewhat limited in telling us how each possible head-to-head matchup would go down. Mainstream college basketball metrics are focused on predicting team efficiency: they measure the margin by which a team would outscore the opponent on a per-possession basis. However, when you pull up the team rankings at EvanMiya.com, KenPom.com, or BartTorvik.com, teams are not technically ranked based on whether they would beat each other, but rather by how many points they would beat an average team in Division 1. When using these metrics to predict game outcomes, there are some statistical assumptions made about how the adjusted efficiency margins work. For example: If Houston is expected to beat an “average team” by 32 points per 100 possessions and Purdue is expected to beat an “average team” by 30 points per 100 possessions, it is assumed that Houston would on average beat Purdue by 2 points per 100 possessions. In real life, it’s not that simple. Many matchup-specific variables can dramatically affect what is likely to happen in any game. Computer models don’t typically account for these variables, nor do they sort team rankings based on who would actually win head-to-head… until now.
Introducing “Relative Ratings” at EvanMiya.com
At EvanMiya.com, I have created a novel, ground-breaking statistical model for rating teams called a “Relative Rating” that accounts for some of these matchup-specific variables and actually ranks teams based on who is predicted to win each possible head-to-head matchup. Each team’s Relative Rating is a number that predicts per-possession efficiency, relative to other teams ranked similarly. If a team is ranked number one, it is because they are predicted to beat every other team in the country in a theoretical matchup based on using team-specific contextual variables to determine likely head-to-head game winners.
There are several new variables specific to each team that more accurately determine how each possible matchup might play out. They are:
Opponent Strength Adjustment: This variable measures how well each team performs above or below expectations based on whether they are playing a really good opponent or a really bad opponent. Some teams perform better than usual when they face really tough teams but struggle to dismantle teams that are worse than them. This concept is sometimes referred to as “playing up/down to competition”. Other teams are the opposite: they can easily crush inferior opponents but are disappointing against higher-quality teams on their schedule. Each team has a variable that measures where they are on this spectrum of playing up or down to their competition.
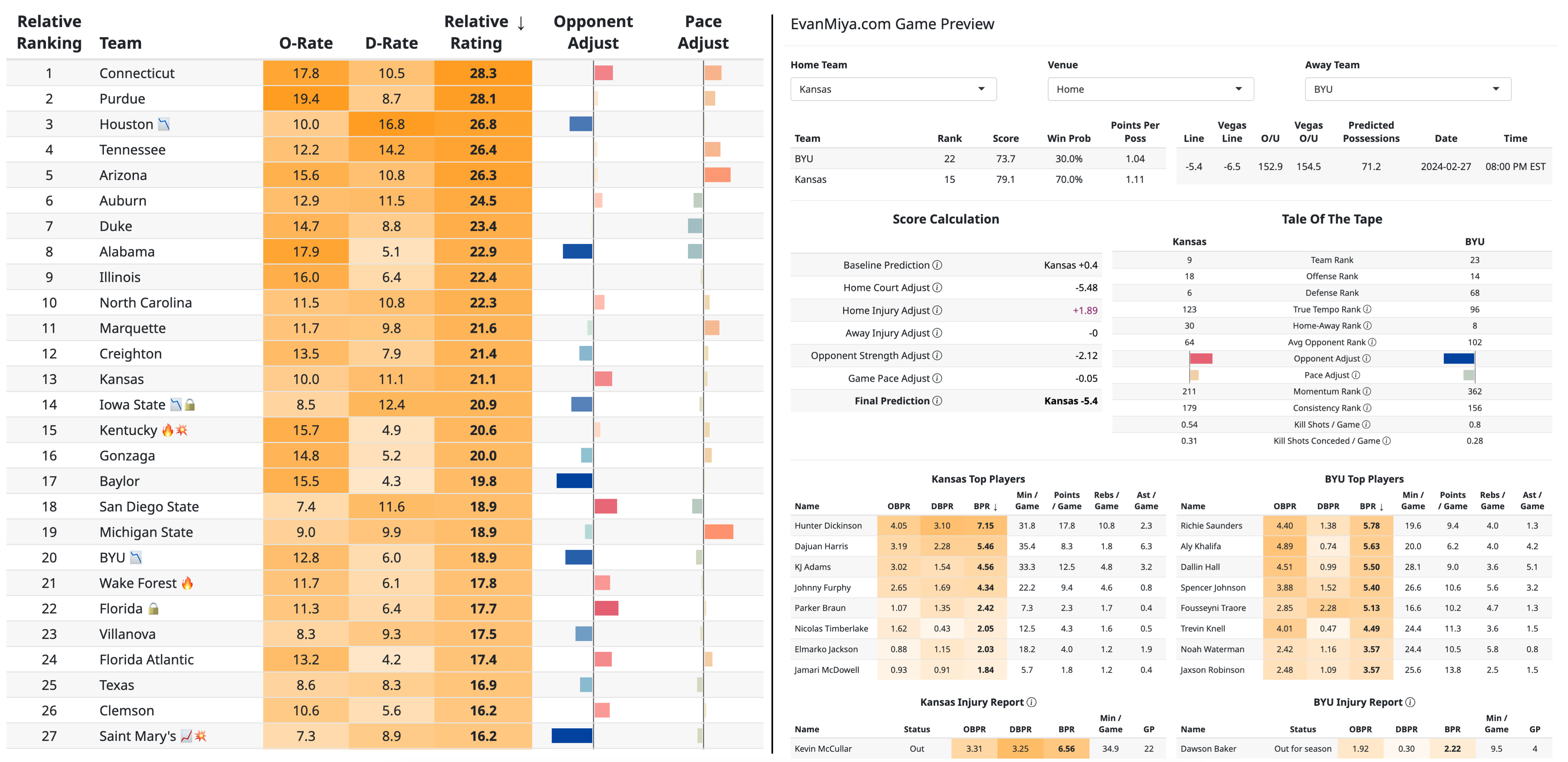
On the Team Ratings page, you can see a horizontal bar for each team under the “Opponent Adjust” column that represents their measurement in this opponent strength metric. A positive bar to the right indicates that a team has better performances against really good teams on the schedule but isn’t as convincing against weaker teams. A negative blue bar indicates that a team plays really well against inferior competition but is disappointing against more elite foes. An example for the Big 12 is shown below:

Big 12 rankings You can also hover over a team’s colored bar to get an explanation (but only when you have selected a specific conference first. The tooltips don’t show up when you are looking at all 360+ D1 teams because it takes too long to load):

To get an even better understanding of how much a game prediction is being altered by the “Opponent Adjustment” variable, you can find the exact amount that the game prediction is being affected in the Score Calculation part of the new Matchup Preview page:

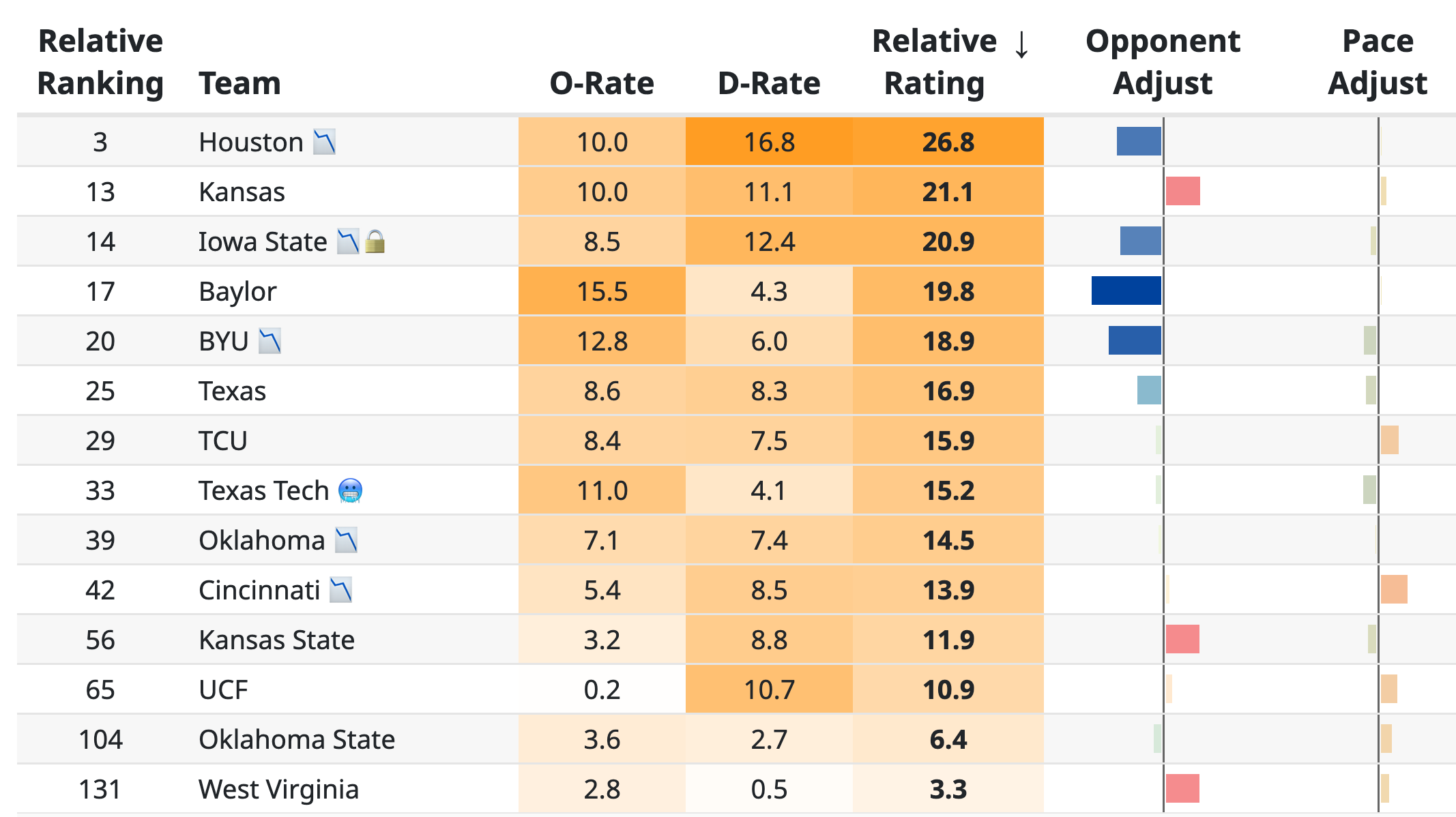
The score calculation part of the Matchup Preview page shows line-by-line adjustments for things like home court advantage, injuries, opponent strength adjustment variables, and game pace adjustment variables Game Pace Adjustment: In a similar vein to the previous variable, this measures how well each team performs above or below expectations in games that are played at a higher or lower pace than usual. Some teams perform slightly better when they play in up-tempo games, and some teams are more comfortable in slow-paced games. Each team has a variable that measures how their game performance changes based on the expected pace of play in a game. These game pace adjustments aren’t as predictive of future team success as the opponent strength adjustments, so these variables don’t influence the game predictions quite as much. An example for the SEC is shown below:

SEC team rankings Recent Form: This variable measures how well each team has been performing lately, putting higher weight on games played recently and down-weighting games further back in the season. Teams that are on a hot streak have a 🔥 emoji next to their name. Teams that are struggling in recent games have a 🥶 next to their name.
Consistency: This variable measures how consistent each team is from game to game. Some teams are more consistent, meaning that their game outcomes are often closer to the predicted outcomes for each game, while other teams have really good and really bad games all over the place. This variable doesn’t affect the game predictions too much, but it does change how much uncertainty we have around each game prediction. If two inconsistent teams are playing against each other, expect the final result to be more unpredictable. Teams that are the most consistent get a 🔒 emoji, and teams that are the most volatile get a 💥 emoji.




You can view each team’s specific rankings in these variables in greater detail on any Matchup Preview page (more on that below).
Sorting Team Rankings
After the team ratings model computes each team’s offensive and defensive strength, as well as the other contextual variables mentioned, the teams are then sorted based on how many other teams they would beat head-to-head. Teams are placed in the order that best reflects who they would be a favorite against and who they would likely lose to. If a team is ranked 35th, they are expected to beat the teams ranked 36th or worse, and lose to the teams ranked 34th or better. However, this doesn’t necessarily mean that the 35th best team is more likely to beat the #1 ranked team than the 36th, 40th, or 45th best team.
For example, at the end of 2022-23, UConn’s Relative Rating was 26.1 (1st in the country), and Houston’s Relative Rating was 24.7 (3rd in the country). However, since UConn’s Opponent Adjustment coefficient indicated that they excelled against good teams (large positive red bar), but struggled against weaker teams, they were only predicted to beat an average D1 opponent by 24.0 points per 100 possessions. By contrast, Houston in 2023 was great at dismantling weaker opponents (large negative blue bar) but struggled against stronger teams. As a result, they were predicted to beat an average D1 opponent by 28.1 points per 100 possessions, a larger margin of victory than for #1 UConn. Against each other, UConn would have been predicted to beat Houston by 3.8 points per 100 possessions.

Historical Examples and Backtesting
To ensure that this new model is an upgrade to my current one, I backtested each season going back to 2015-16 to make sure that the model would have predicted better game scores on average, based on the data it would have had before each day of games. To read more about this methodology, refer to the Game Predictions article here.
Two pertinent examples from the 2022-23 season illustrate the value of this new Relative Ratings model:
The infamous 16 seed Fairleigh Dickinson upset over 1 seed Purdue. No one could have reasonably expected FDU to beat Purdue, but the “Opponent Adjustment” variable would have revealed that an upset was slightly more likely than Vegas anticipated. Heading into the tournament, Purdue was playing better against stronger teams but was underperforming against weaker teams on their schedule. Fairleigh Dickinson was the same: it was producing some of its better games against the toughest opponents on their schedule in the regular season. This boded well for FDU’s chances against an elite team in Purdue. While the Vegas line closed at Purdue -23.5, the algorithm at EvanMiya.com would have shown Purdue as only a 20.2-point favorite, specifically because of a 2-point lean towards FDU entirely based of the Opponent Adjustment variable for both teams.
Miami made the Final Four in 2023 after winning against several very good teams, despite having somewhat of a rocky regular season. Coming into the tournament, they were ranked 6th in the country in Opponent Adjustment, which means that they played really well against elite teams but failed to show up in some of their easiest games. They were a prime candidate to be upset in the first round by 12-seed underdog Drake (Miami trailed by 8 with 5:40 remaining), but if they could escape their first game, they had lots of potential to play their best against the strongest teams in their region. When they reached 1 seed Houston in the Sweet 16, the algorithm at EvanMiya.com would have predicted Miami to only be 5.5 point underdogs, compared to the Vegas line of Houston -8.5.
What This Means for March Madness
I will do a much more in-depth study of how the Relative Ratings impact which teams could do well in the tournament, but there are a couple key guidelines:
Upsets from “cinderellas” are more likely to come from teams that have a positive Opponent Adjustment rating, as these teams often play much better against tough competition. They will be more ready for the biggest foes.
Top seeds (1-6) who have negative Opponent Adjustment ratings are more likely to handle business in the early rounds and win at least a game or two against weaker teams. They aren’t as prone to being toppled by upset bids. However, they aren’t prime candidates to make a deep run to the Final Four or beyond if they have to face other elite teams.
Top seeds who have a positive Opponent Adjustment rating are the better picks to make a deep run in the tournament… if they can survive the first game or two. These teams play their best in the biggest games but aren’t as convincing when they are comfortable favorites.
The New Matchup Preview Page
An equally huge part of this release is an all-new Matchup Preview Page, which will help explain how the new Relative Ratings model works in action but will also provide some other great tools, including:
A line-by-line score calculation table that shows how much specific variables affect the game prediction, such as home court adjustments, adjustments for injured players, and opponent strength and game pace adjustments
A “Tale of the Tape” team comparison
Roster summaries with key stats
Injury reports for each team
Predicted number of possessions and per-possession efficiency for each team
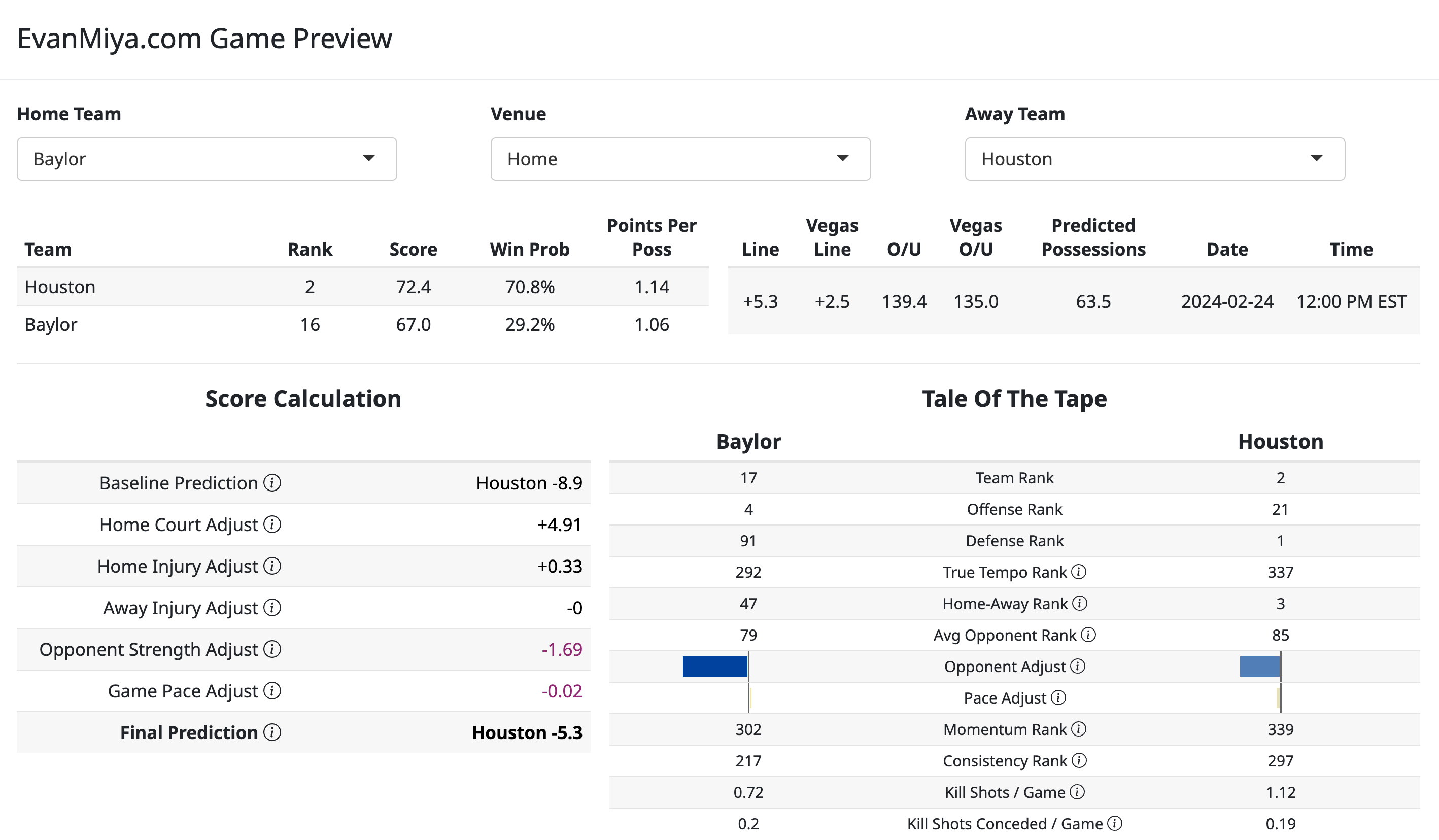

You can find each matchup preview by clicking on the game listing on the Game Predictions page. There will be more features added to this in the near future, such as the ability to edit the injury report, generating a matchup preview for any possible game, not just ones on the schedule, and adding game-specific keys to victory.
Dive into all of the new tools at EvanMiya.com! I’ll be putting more analysis out in the coming weeks that digs into the new team ratings model even further.
Love following everything you post here and on the site. Got a question for you on the Opponent Strength Adjustment component, if you get a second.
I'd imagine that for major conference teams (and probably low majors in the reverse direction - but who cares about them), opponent strength and date of matchup might be somewhat correlated - with most playing the weakest parts of their schedule during the non-con season. If teams do not really change over the course of the season, that's a moot point. Or if there's enough strength variation within-conference, that's also probably moot. But I think there's an argument that both of those assumptions would be incorrect.
And two related concerns: 1) The lowest Big 12 team is 141 in your rankings, how reliable would the Strength Adjustment be outside of that range? 2) All Big East teams are above 73 in your rankings (except Georgetown at 182 and DePaul at 307); are games against those two teams have disproportionately high influence on the rating?
I am not questioning your model, it just seems hard to estimate! (Maybe not if I had a statistics PhD, haha.) Is there is a simple-ish enough explanation for why these are not concerns?
Ry Daw's above comment is quite probative. Would very much appreciate Evan's response when time permits.